Distributed Training Framework
This project implements a Federated Learning Framework that enables distributed machine learning across multiple machines while maintaining data privacy and security. The system allows model training on decentralized data without requiring data to leave local machines.
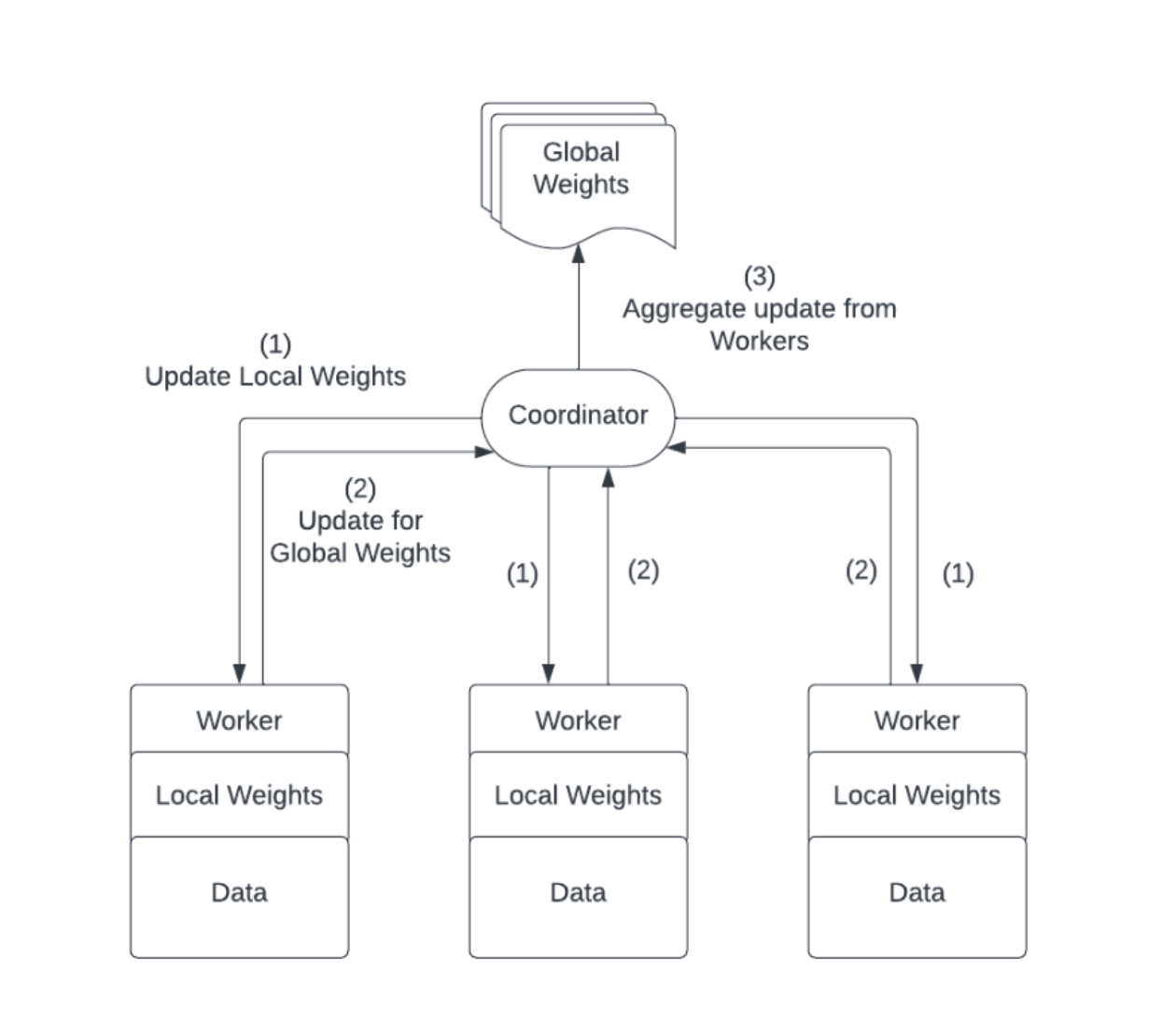
Architecture
- Coordinator: Manages the global model and orchestrates training rounds
- Workers: Train models on local data and send updates to the coordinator
- Aggregation: Uses federated averaging, effective for both homogeneous and heterogeneous data
Implementation
- Built with Python, XML-RPC, and PyTorch
- Inspired by MapReduce for modularity and customizability
- Language and framework agnostic design
- Clean separation between ML code and coordination logic
Key Features
- Load Balancing: Detects stragglers and dynamically adjusts workloads
- Fault Tolerance: Built-in retry mechanisms and quorum protocol for worker failures
- Scalability: Tested on AWS EC2 with deployment scripts for multi-machine setups
The framework was evaluated on MNIST with varied data distributions across workers, demonstrating robust performance and resilience to worker failures.